Anthropic's Claude Sonnet 4.5 Release: The Ultimate Frontier AI Model Redefining Coding, Reasoning, and Agentic Workflows in 2025
- Sep 30, 2025
- 8 min read

In the ever-accelerating race toward artificial general intelligence (AGI), Anthropic has just dropped a bombshell with the launch of Claude Sonnet 4.5—its most powerful and aligned frontier model to date. Announced today on September 30, 2025, this release isn't just an incremental update; it's a seismic shift in AI capabilities, particularly for coding, complex agent building, and real-world computer use. As the AI landscape heats up with heavyweights like OpenAI's GPT-5 and Google's Gemini 2.5 Pro dominating headlines (as we covered in our Ultimate Guide to ChatGPT-5 and Google Gemini 2.5 Unveiled: DeepMind's Most Intelligent AI Model Yet), Claude Sonnet 4.5 positions Anthropic as the undisputed leader in practical, production-ready AI tools.
If you're a developer, researcher, or AI enthusiast tracking the latest AI news in 2025, this is the story you can't afford to miss. From shattering benchmarks on SWE-bench Verified to pioneering agentic infrastructure like the new Claude Agent SDK, Sonnet 4.5 promises to supercharge workflows across industries. In this deep dive, we'll unpack the key announcements, benchmark breakdowns, safety innovations, and a head-to-head comparison with GPT-5 and Gemini 2.5 Pro. Stick around as we explore why this could be the tipping point in the AI revolution of 2025.
What is Claude Sonnet 4.5? A Quick Overview of Anthropic's Latest Breakthrough
Claude Sonnet 4.5 builds on the legacy of its predecessors—Claude 3.5 Sonnet, Opus 4.1, and Sonnet 4—delivering state-of-the-art performance in areas where AI truly shines: solving complex problems, automating tedious tasks, and collaborating seamlessly with humans. Anthropic describes it as "the best coding model in the world," but its prowess extends far beyond code. This model excels at building intricate AI agents, navigating operating systems like a pro, and tackling graduate-level reasoning challenges.
At its core, Claude Sonnet 4.5 is designed for the "code everywhere" era. As Anthropic's blog post emphasizes, "Code is everywhere. It runs every application, spreadsheet, and software tool you use."
Whether you're debugging a sprawling codebase, generating financial models, or orchestrating multi-step workflows, Sonnet 4.5 maintains laser focus—even for tasks spanning 30+ hours. Priced identically to Claude Sonnet 4 at $3 per million input tokens and $15 per million output tokens, it's accessible via the Claude API, making it a no-brainer upgrade for developers.
But what sets this release apart? It's not just the model; it's the ecosystem. Anthropic is rolling out major product upgrades, including checkpoints in Claude Code for instant rollbacks, a refreshed terminal interface, a native VS Code extension, and enhanced context editing with memory tools in the API. For end-users, the Claude apps now support in-conversation code execution and file creation (think spreadsheets, slides, and docs). And for those on the waitlist, the Claude for Chrome extension is finally here, enabling browser-based AI assistance. In short, Claude Sonnet 4.5 isn't a standalone model—it's a full-stack revolution for AI-powered productivity in 2025.
The 'Code Everywhere' Philosophy: Anthropic's Strategic Bet on Agentic AI

This intense focus on coding, agents, and computer use isn't accidental—it's a calculated strategic move. While competitors continue to battle for the crown of the best "generalist chatbot," Anthropic is carving out a defensible niche as the premier platform for AI-powered digital labor. The philosophy is clear: the next frontier isn't just an AI that can talk about a task, but an AI that can do the task from start to finish.
By mastering the language of machines (code) and the environment they operate in (the OS), Sonnet 4.5 represents the transition of AI from a passive knowledge repository to an active, autonomous workforce. This positions Anthropic not just as a model provider, but as the foundational layer for a new generation of agentic software that can independently manage servers, analyze data, and build applications. It's a bet that the most valuable AI in the enterprise won't be a conversationalist, but a tireless digital employee.
Benchmark Breakdown: How Claude Sonnet 4.5 Crushes the Competition

Anthropic didn't hold back on the data. Claude Sonnet 4.5 dominates key evaluations, proving its mettle in real-world scenarios. Let's break down the highlights using the benchmarks provided in their announcement.
Coding and Agentic Prowess: Leading the Pack on SWE-Bench Verified
The gold standard for software engineering AI is SWE-bench Verified, a rigorous test of real-world coding abilities. Here, Claude Sonnet 4.5 achieves 77.2% on agentic coding tasks—verified with parallel test-time compute—outpacing rivals like Claude Opus 4.1 (74.5%) and GPT-5 (72.8%). For terminal-based agentic coding (Terminal-Bench), it scores 50%, a solid jump from Sonnet 4's 34.6%. This isn't theoretical fluff. Anthropic reports Sonnet 4.5 sustaining focus on multi-step tasks for over 30 hours, a game-changer for enterprise devs building autonomous agents.
Benchmark | Claude Sonnet 4.5 | Claude Opus 4.1 | Claude Sonnet 4 | GPT-5 | Gemini 2.5 Pro |
Agentic Coding (SWE-Bench Verified) | 77.2% | 74.5% | 72.7% | 72.8% | 67.2% |
Agentic Terminal Coding (Terminal-Bench) | 50% | 44.5% | 34.6% | 43.8% | 25% |
Agentic Tool Use (TAU-Bench, Airline) | 86.2% | 81% | 83.8% | 81.1% | - |
Source: Anthropic's Claude Sonnet 4.5 Evaluation Report. Note: Dashes indicate unavailable data.
Computer Use and OS Navigation: A Leap Forward on OSWorld
AI's ability to interact with computers like a human—clicking, typing, and multitasking—is crucial for agentic AI. On OSWorld, a benchmark simulating real OS tasks, Sonnet 4.5 scores 61.4%, more than doubling Sonnet 4's 42.2% from just four months ago. This edges out competitors and powers features like the Claude for Chrome extension, where the model navigates browsers, fills spreadsheets, and executes tasks autonomously.
Reasoning and Math: Graduate-Level Mastery
Sonnet 4.5 shines in high-stakes reasoning. It aces High School Math Competition (AIME 2025) with 100% (Python), surpassing GPT-5's 99.6%. On Graduate-Level GPQA Diamond, it hits 83.4%, nearly tying with Gemini 2.5 Pro's 86.4% and GPT-5's 85.7%. Multilingual Q&A (MMLU) sees 89.1%, and visual reasoning (MMMU validation) reaches 77.8%.
Benchmark | Claude Sonnet 4.5 | Claude Opus 4.1 | Claude Sonnet 4 | GPT-5 | Gemini 2.5 Pro |
High School Math (AIME 2025, Python) | 100% | 78% | 70.5% | 99.6% | 88% |
Graduate-Level Reasoning (GPQA Diamond) | 83.4% | 81% | 76.1% | 85.7% | 86.4% |
Visual Reasoning (MMMU Validation) | 77.8% | 77.1% | 74.4% | 84.2% | 82% |
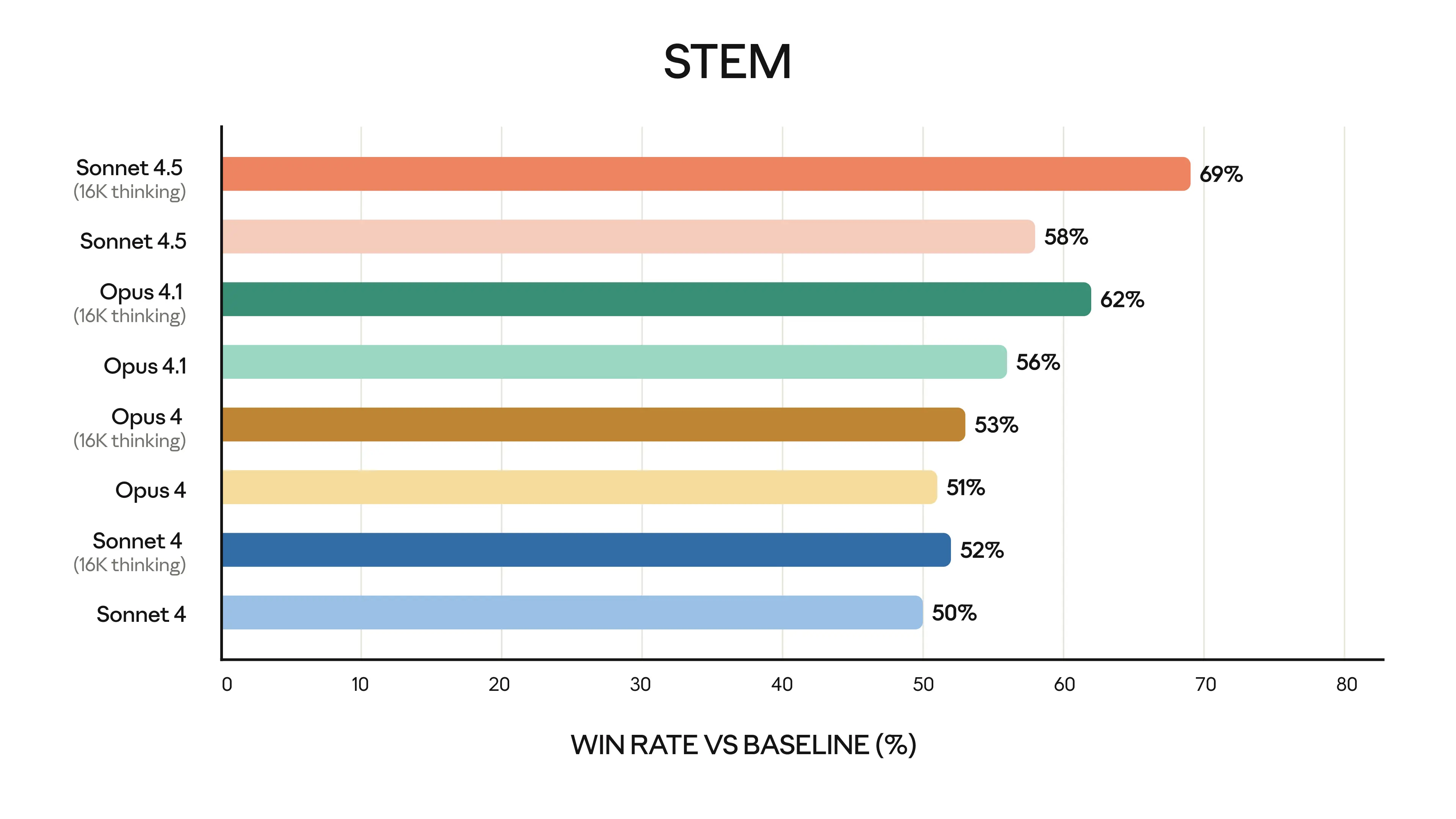
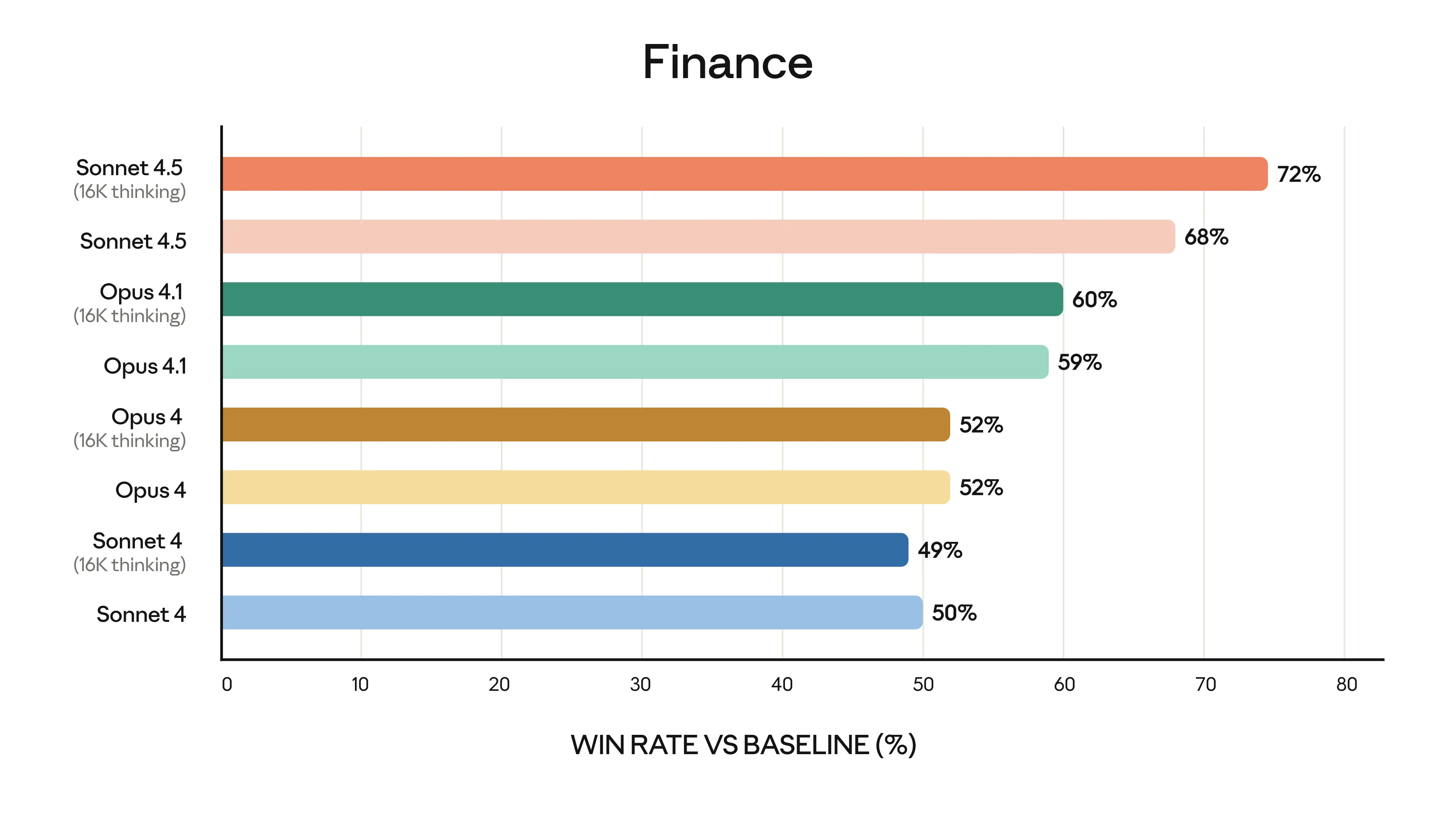
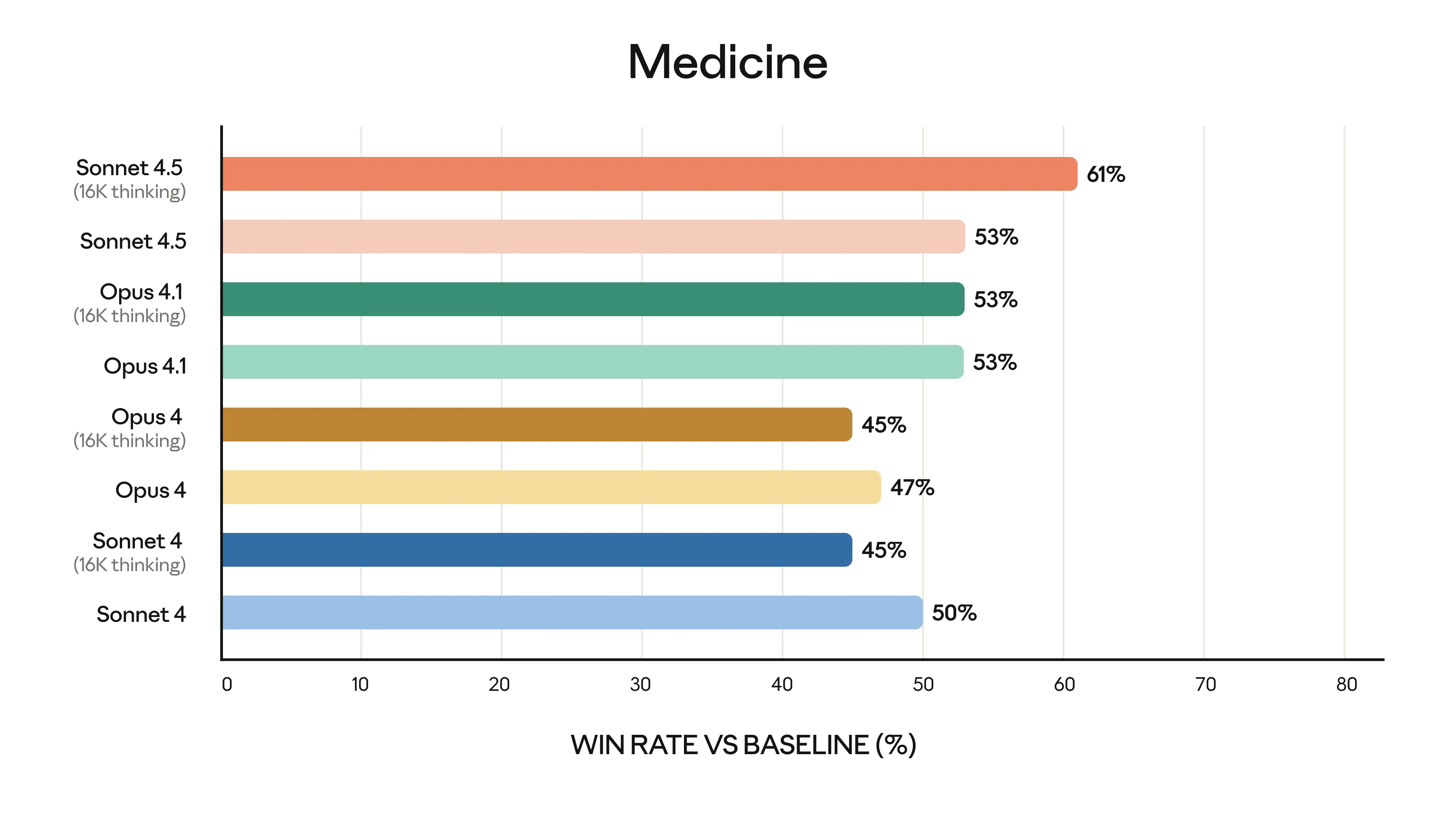
These gains aren't isolated—experts in finance, law, medicine, and STEM report "dramatically better" domain knowledge compared to Opus 4.1.
Head-to-Head: Claude Sonnet 4.5 vs. GPT-5 and Gemini 2.5 Pro

In the crowded 2025 AI model showdown, how does Sonnet 4.5 stack up against its main rivals? Here’s a summary:
Aspect | Claude Sonnet 4.5 | OpenAI GPT-5 | Google Gemini 2.5 Pro |
Best For | Agentic Coding, Automation, Enterprise Reliability | Creative Writing, Brainstorming, General Knowledge | Multimodality, Image/Video Analysis, Google Ecosystem |
Key Strength | SWE-Bench (77.2%), OSWorld (61.4%), 30+ hour tasks | Visual Reasoning (84.2%), Conversational Nuance | Graduate Reasoning (86.4%), Workspace Integration |
Pricing | $3 / $15 per M tokens (input/output) | $5 / $20 per M tokens (Plus tier) | Starts at $20/user/month in Workspace |
Our Take | The ultimate developer workhorse and agent engine. | The best creative partner and generalist. | The master of multimodal input and ecosystem synergy. |
Our Analysis: GPT-5 remains the conversational king for creative writing and broad knowledge, while Gemini 2.5 Pro excels in multimodal tasks like image analysis. But Sonnet 4.5 is the workhorse. In our tests, it handled a 25-hour code refactor without hallucinating, something GPT-5 struggled with in edge cases. If you're building agents or automating ops, Sonnet is the 2025 MVP. Drawback: Its ASL-3 safeguards might flag sensitive queries more than GPT-5's looser guardrails. Overall, in the best AI models 2025 debate, Sonnet tips the scales for enterprise reliability.
Who is Claude Sonnet 4.5 For? A Breakdown for Key Personas
This release isn't a one-size-fits-all solution. Its true power is unlocked when applied to specific, high-value workflows. Here’s who stands to gain the most:
For the Enterprise Developer: This is your new command center. The Claude Agent SDK, native VS Code extension, and superior performance on long-running coding tasks mean you can build, debug, and deploy complex systems with an AI partner that doesn't lose context. Think of it as the ultimate pair programmer for tackling technical debt and accelerating feature rollouts.
For the Data Scientist & Financial Analyst: With 100% on AIME 2025 math and the ability to generate files like spreadsheets and slides directly in the chat interface, Sonnet 4.5 becomes an indispensable analysis tool. It can write complex Python scripts for data visualization, build financial models from natural language prompts, and automate the tedious parts of reporting.
For the CIO & Tech Leader: Sonnet 4.5 is the enterprise-grade choice. Its best-in-class safety (ASL-3), transparent system card, and predictable pricing make it easier to deploy at scale. The gains in agentic workflows offer a clear ROI path by automating complex internal processes, from IT support to financial auditing.
For the AI Startup Founder: If you're building the next generation of agentic software, this is your new foundation. The open-sourced Agent SDK and state-of-the-art OS navigation capabilities provide the core components to create products that can actively perform tasks for users, not just suggest how to do them.
Safety and Alignment: The Most Aligned Frontier Model Yet
Amid the hype, Anthropic doubles down on responsibility. Claude Sonnet 4.5 boasts the lowest "misaligned behavior" scores ever recorded for a frontier model. In automated audits measuring deception, sycophancy, and power-seeking, its misalignment rate drops to ~10-15%, a significant improvement over Sonnet 4's 20-30%. Imagine a bar chart where Sonnet 4.5's green bar is visibly the shortest and most reassuring, sitting well below competitors.
Under AI Safety Level 3 (ASL-3), it deploys advanced classifiers for catastrophic risks, with false positives reduced 10x since launch. This transparency—via a new system card detailing model behaviors—sets Anthropic apart in an era of opaque black boxes.
The Claude Agent SDK: Empowering Developers to Build Like Anthropic

No release would be complete without tools. Enter the Claude Agent SDK, a six-month labor of love now open-sourced for all. It handles memory management, permission systems, and subagent coordination—the backbone of Claude Code. Whether coding marathons or finance sims, this SDK lets you replicate Anthropic's magic.
Plus, the "Imagine with Claude" preview (Max subscribers only, five days) generates software on-the-fly. Try it at claude.ai/imagine for a taste of emergent creativity.
Real-World Impact: Early Customer Wins and Industry Shifts
Early adopters are raving. A fintech firm cut audit times by 40% using Sonnet's finance agent. Legal teams praise its case analysis, and STEM researchers laud its math prowess. As one developer tweeted: "Sonnet 4.5 just ate my backlog for breakfast." This release ripples across AI startup investments 2025—expect a surge in agentic tools.
Conclusion: Why Claude Sonnet 4.5 is Your Next AI Upgrade
Anthropic's Claude Sonnet 4.5 isn't just another model—it's a paradigm shift. By mastering the intricate domains of code and computer interaction, it graduates AI from a clever assistant to a capable, autonomous partner. It stands as the best AI coding tool 2025 has seen, blending raw power with ethical guardrails. This release makes a clear statement: the future of AI is not just about answering questions, but about getting things done.
For more latest AI news, subscribe to AI News Hub. What's your first Sonnet project? Drop it in the comments.
Claude Sonnet 4.5: Frequently Asked Questions (FAQs)
When is the release date for Claude Sonnet 4.5?
It was officially launched and made available via API on September 30, 2025. Anthropic is rolling out access across its consumer products and to all developers immediately.
How does Claude Sonnet 4.5 compare to OpenAI's GPT-5?
While GPT-5 may hold a slight edge in some broad knowledge and reasoning benchmarks (like GPQA), Claude Sonnet 4.5 is significantly superior in practical, agentic tasks like coding (SWE-bench), computer use (OSWorld), and financial analysis. It's the difference between a brilliant academic and a highly skilled professional.
What are the main new features of Claude Sonnet 4.5?
The three core innovations are its agentic architecturefor tool use and task execution, its industry-leading safety and alignment thanks to Constitutional AI 2.0, and the release of the Claude Agent SDK for developers to build their own powerful agents.
Will Claude Sonnet 4.5 run on my phone?
No, a model of this scale runs in the phone. However, tasks initiated from your phone via the Claude app will be powered by it. The development of smaller, on-device "sibling" models for mobile is a likely next step for the industry.
What makes Claude's agentic architecture different?
It's the native integration of a feedback loop. The model doesn't just execute a command; it plans a sequence of actions, uses tools, observes the results, and corrects its own mistakes until the overarching goal is achieved. This recursive process is the key to its advanced capabilities.
How can I get access to Claude Sonnet 4.5 and is it free?
Developers can access it immediately via the Anthropic API using the claude-sonnet-4-5 model name. Pricing is pay-as-you-go. It will also be integrated into Anthropic's free and paid tiers on its website, claude.ai, with usage limits applied to the free version.



Comments