Synthetic Data Revolution: How AI-Generated Data is Solving Privacy and Scaling Innovation in 2025
- Aug 11, 2025
- 7 min read

In 2025, artificial intelligence is facing a paradox. AI models, especially large language models (LLMs) like GPT-5, are hungrier than ever, demanding trillions of data points to learn. Yet, the real-world data they crave is a minefield—locked away by privacy laws like GDPR and HIPAA, riddled with hidden biases, or simply too rare to collect. It's a crisis of scarcity in an age of information overload.
The solution? Don't find more data. Create it.

Enter synthetic data: artificially generated information that's poised to solve AI's biggest problems. This isn't just a niche fix; it's a full-blown revolution. With the global market projected to skyrocket to $6.6 billion by 2034, synthetic data is shifting from a backup plan to the cornerstone of ethical, scalable, and innovative AI. Let's dive in.
What Exactly is Synthetic Data?

Think of synthetic data as a highly realistic digital twin of real-world information. It's artificially created by AI algorithms to mirror the statistical patterns, relationships, and structures of a real dataset without containing a single shred of actual, personal information.
How is it made? Through powerful AI techniques like:

Generative Adversarial Networks (GANs): Imagine an art forger (the "generator") creating fake paintings, while a detective (the "discriminator") tries to spot them. They compete and learn from each other until the forger's paintings are indistinguishable from the real thing. That's how GANs create ultra-realistic data.
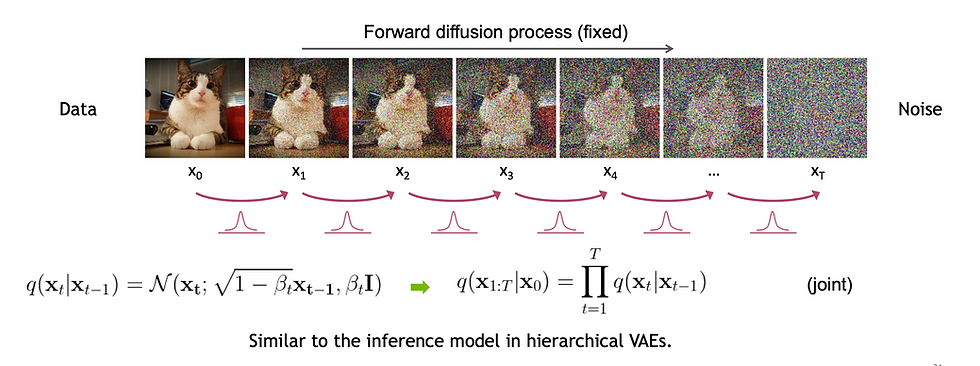
Source: GitHub Variational Autoencoders (VAEs) & Diffusion Models: These are other advanced methods that learn the underlying essence of a dataset and can then generate new, unique data points from that learned representation.
The result is a dataset that's mathematically sound and perfect for training AI models, but with zero privacy risk. Unlike anonymized data, which can sometimes be re-identified, synthetic data is built from the ground up, making it inherently safe.
Why It's a Game-Changer
Bulletproof Privacy: It completely bypasses privacy regulations like the EU AI Act and HIPAA, as it contains no real personal data.
Radical Cost Reduction: Slashes data collection and labeling costs by a staggering 80%, accelerating development cycles from months to weeks.
Engineered Fairness: Real data is often biased. Synthetic data can be perfectly balanced to remove demographic biases, leading to fairer AI in areas like loan applications and medical diagnoses.
Infinite Scalability: Need to train a self-driving car for a "black swan" event like a moose crossing the road during a blizzard? You can generate thousands of such scenarios, something impossible to collect in the real world.
A Quick Technical Dive: GANs vs. VAEs vs. Diffusion Models
The magic behind synthetic data comes from generative models. A recent breakthrough study from Stanford's AI Lab highlighted how combining these models can create "hybrid-synthetic" data with unprecedented fidelity. However, each technique has its trade-offs:
Method | Best For | Quality | Speed | Cost |
GANs | Images, complex patterns | High | Medium | High |
VAEs | Structured data, tables | Medium | Fast | Low |
Diffusion Models | High-resolution images | Highest | Slow | Highest |
Choosing the right model depends on balancing the need for data quality against the constraints of budget and development time.
The ROI of Synthetic Data: A Concrete Example

Consider an AI startup building a medical diagnostic tool requiring 50,000 patient records:
Traditional Approach:
Cost per record (acquisition, labeling, anonymization): $150
Total Cost: 50,000 records × $150/record = $7.5 Million
Synthetic Approach:
Upfront cost (generator model development, compute): $500,000
Cost per generated record (marginal compute): $2
Total Cost: $500,000 + (50,000 records × $2) = $600,000
In this scenario, the startup saves $6.9 million upfront. More importantly, the scaling economics are transformed. The next 100,000 records would only cost an additional $200,000, while the traditional approach would cost another $15 million.
Where Synthetic Data is Making Waves in 2025
Synthetic data isn't just a theory; it's already transforming major industries.
1. Revolutionizing Healthcare
Patient data is a fortress, and for good reason. Synthetic data provides a key.
Mayo Clinic is already saving an estimated $10 million annually by using synthetic electronic health records (EHRs) to train diagnostic models without touching sensitive patient files.
Drug discovery is being supercharged by simulating clinical trial outcomes, potentially cutting trial costs by 30% and bringing life-saving drugs to market faster.
AI models are learning to detect rare diseases from synthetic X-rays and MRIs, a task that would otherwise suffer from a lack of real-world examples.
2. Fortifying Finance

In a world of tight regulations and rampant fraud, synthetic data is the new security standard.
JPMorgan boosted its fraud detection accuracy by 15% using synthetic transaction data, catching criminals without exposing customer details.
Banks are stress-testing their anti-money laundering (AML) systems with simulated financial records, ensuring they are compliant with tough new regulations.
Credit scoring models are being trained on bias-free synthetic datasets, paving the way for fairer lending decisions.
3. Powering Autonomous Vehicles 🚗
You can't have a self-driving car learn on the job. Simulation is everything.
Tesla and Waymo rely heavily on synthetic data to train their cars for millions of miles in virtual worlds, simulating edge cases like sudden pedestrian crossings or extreme weather. This has improved safety in simulations by 20%.
NVIDIA's Omniverse platform, a powerhouse for creating photorealistic 3D worlds, now generates an estimated 50% of the training datasets used for autonomous vehicles.
4. Fueling China's Tech Boom 🏙️
China is betting big on synthetic data. DataGrand, a leading startup, is at the forefront.
It provides synthetic customer profiles to e-commerce giants like Alibaba, helping them predict trends and boost conversion rates by 10%.
This technology is a core part of China's $1 billion investment in synthetic data to build smarter cities, optimizing everything from traffic flow to public services.
The Titans of Synthetic Data
A few key companies are leading the charge and shaping the industry.
NVIDIA: The king of simulation. Its Omniverse platform is the gold standard for creating the hyper-realistic 3D "digital twins" needed for training robots and autonomous vehicles.
Gretel: The democratizer. With its open-source platform and a fresh $50 million in funding, Gretel is making privacy-preserving AI accessible to everyone, from startups to large enterprises.
Mostly AI: The European champion. This company specializes in GDPR-compliant synthetic data, serving 40% of EU banks and ensuring innovation aligns with Europe's strict privacy laws.
DataGrand: The Eastern powerhouse. Focused on Asia's booming e-commerce and smart city markets, DataGrand is a critical player in the global AI race.
The Hurdles to Overcome
Hurdles to Overcome: A Risk & Mitigation Framework

Synthetic data isn't a magic bullet. Deploying it successfully requires a clear understanding of the risks and a robust plan to mitigate them.
The Fidelity Gap & Distribution Shift: The synthetic data must accurately reflect the real world. Distribution shift occurs when the real world changes (e.g., new customer behaviors emerge) but the synthetic data doesn't, making the AI model less accurate over time.
Mitigation: Implement continuous monitoring and regenerate the synthetic dataset periodically based on fresh (but smaller) samples of real-world data.
Model Collapse in GANs: This is a common training failure where the generator finds a loophole and produces only a limited variety of samples (e.g., only generating images of one type of dog).
Mitigation: Use advanced GAN architectures and monitoring techniques during training to ensure output diversity. Human-in-the-loop validation is critical for quality assurance.
Intellectual Property Concerns: A new legal frontier is emerging: who owns synthetic data? If generated from a company's proprietary dataset, does it constitute a "derivative work"?
Mitigation: Work with legal teams to establish clear data governance and IP policies. Many are turning to data generated from fully open-source material to avoid ambiguity.
The Next Frontier: What's Ahead?

The future of synthetic data is incredibly bright. Here’s what to expect:
Explosive Growth: Gartner predicted that by 2024, 60% of data for AI will be synthetic, and estimates that synthetic data will completely overshadow real data in AI models by 2030.
Even Better AI Tools: Next-generation GANs and diffusion models will produce data that is virtually indistinguishable from reality, closing the fidelity gap.
Data Marketplaces: Platforms like Dedomena AI's Cortex are emerging, creating a "stock market" for compliant, ready-to-use synthetic datasets that any organization can buy.
Regulatory Clarity: The EU AI Act, which began implementation in 2025, establishes transparency requirements for synthetic content, requiring AI-generated outputs to be clearly marked as artificially generated.
Conclusion: The Future is Synthetic
Synthetic data is the elegant solution to AI's data paradox. It unlocks innovation by providing an abundant, privacy-safe, and fair alternative to real-world data. From NVIDIA's virtual worlds to Gretel's open-source tools, this technology is no longer on the horizon—it's here, powering the smartest and safest AI systems we've ever seen.
The question is no longer if synthetic data will become mainstream, but how quickly you can adapt.
What do you think is the most exciting application of synthetic data? Share your thoughts on AI News Hub or LinkedIn and join the conversation!
FAQs About Synthetic Data
What is synthetic data in simple terms?
It's artificially created data that statistically mirrors real data. Think of it as a realistic "stunt double" for sensitive information, allowing AI to train safely.
Why not just use anonymized data?
Anonymization can often be reversed, posing a privacy risk. Synthetic data is created from scratch, so it has no links to real individuals, offering true privacy.
What are the main benefits?
It solves privacy issues, drastically cuts costs (by up to 80%), reduces bias for fairer AI, and allows developers to create data for rare scenarios.
Is synthetic data always accurate?
Quality can vary. The best systems use human oversight to ensure the data is a high-fidelity match to reality. Inaccuracies can be a risk with lower-quality models.
Who are the main companies in this space?
Key players include NVIDIA (for 3D simulations), Gretel (for open-source tools), Mostly AI (for European financial compliance), and DataGrand (for Asia's e-commerce market).


Comments