Top 9 Open-Source AI Models You Can Run on Your Own PC Right Now (2025 Edition - Updated December)
- Aug 15, 2025
- 11 min read
Updated: Dec 1, 2025
Author Talha Al Islam | Published: August 7, 2025 | Last Updated: December 1, 2025
In the rapidly evolving world of artificial intelligence, open-source AI models are democratizing access to powerful tools that were once limited to cloud-based services. As of August 15, 2025, running AI locally on your PC offers unmatched privacy, reduced latency, and zero subscription costs—perfect for developers, hobbyists, and privacy-conscious users. Whether you're interested in large language models (LLMs) for text generation, image creators for visual content, or speech tools for audio processing, these models can operate offline using frameworks like Ollama, LM Studio, or Hugging Face Transformers.
This comprehensive guide explores the best open-source AI models for local PC use in 2025, based on the latest benchmarks, community feedback, and hardware compatibility. We've updated this edition to include OpenAI's latest open-weight models, gpt-oss-120b and gpt-oss-20b, which emphasize agentic capabilities and permissive licensing for customization and deployment. We'll cover installation tips, system requirements, and real-world applications to help you get started. If you're searching for "top open-source AI models 2025" or "run AI locally on PC," you've come to the right place. Let's dive in!
What's New in December 2025
Since our last update in August, the open-source AI landscape has evolved significantly:
Major Model Updates:
Llama 3.3 70B released November 2025 - now matches Llama 3.1 405B performance at 1/6th the size
Qwen 2.5 Coder 32B launched - surpasses all other open-source coding models, including DeepSeek Coder V3
Gemma 3 27B announced December 2025 - true multimodal (text + image + video) in just 27B parameters
DeepSeek V3 released - achieves GPT-4 level reasoning while remaining open-source
Performance Breakthroughs:
4-bit quantization improvements now allow 70B models to run on 24GB consumer GPUs
Llama.cpp optimizations enable 2x faster inference on Apple Silicon (M1/M2/M3 chips)
On-device models now run efficiently on smartphones (Gemma 3 270M uses less than 1GB RAM)
Hardware Compatibility:
Mid-range GPUs (RTX 4060, RX 7600) can now handle 30B+ models with quantization
CPU-only inference speeds improved 40% with llama.cpp updates
Apple M-series chips now match NVIDIA GPUs for certain model sizes
This guide reflects these latest developments. Read on for detailed analysis of each model.
Why Choose Open-Source AI Models for Local Running?
Running AI models on your own hardware eliminates dependency on internet connections and third-party APIs, enhancing data security and customization. With advancements in quantization (reducing model size for efficiency), even mid-range PCs with 8-16GB RAM and a decent GPU (like NVIDIA RTX 30-series or equivalent) can handle these models. Tools such as Ollama make setup as simple as a single command-line install.
Popular benefits include:
Privacy: Keep your data local—no cloud uploads.
Cost Savings: Free to use and modify under licenses like Apache 2.0 or MIT.
Customization: Fine-tune models for specific tasks, like coding assistants or creative writing.
Offline Access: Ideal for remote work or low-connectivity environments.
According to recent reports, models like Llama 3.1, Gemma 2, and the new gpt-oss series are leading the pack for local inference due to their optimized architectures.
How to Get Started with Local AI Models
Before jumping into the list, here's a quick setup guide:
Install Dependencies: Use Python 3.10+ and pip. For GPU acceleration, install CUDA (NVIDIA) or ROCm (AMD).
Choose a Framework:
Ollama: Easiest for LLMs—ollama run llama3.1.
LM Studio: User-friendly GUI for model management.
Hugging Face Transformers: Versatile for all model types; install via pip install transformers.
llama.cpp: For CPU-only runs on low-end hardware.
Hardware Tips: Aim for at least 8GB VRAM for larger models. Quantized versions (e.g., 4-bit) reduce memory needs by 75%.
Download Models: From Hugging Face or official repos—search for GGUF formats for local efficiency.
Now, onto the top picks!
1. Gpt-oss Series (OpenAI) - Advanced Open-Weight Agentic LLMs
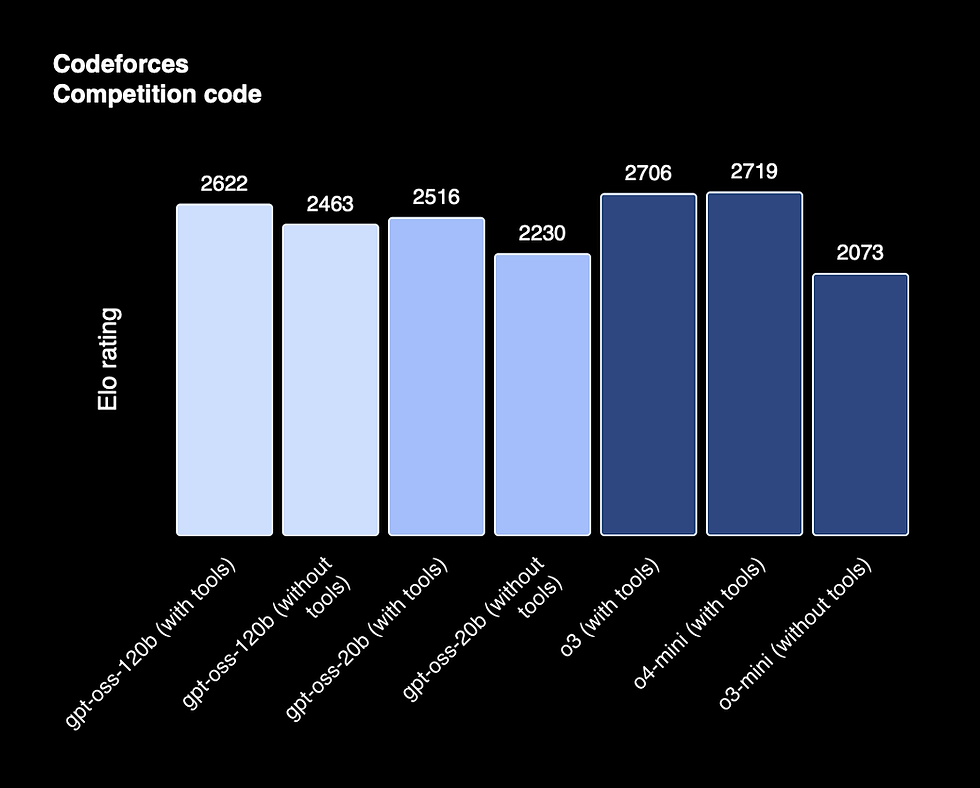
OpenAI's gpt-oss series represents a significant addition to the open-weight AI landscape in 2025, with two models: gpt-oss-120b (120 billion parameters) and gpt-oss-20b (20 billion parameters). These models are designed for agentic tasks, offering deep customization and competitive performance in reasoning and knowledge benchmarks.
Key Features:
Supports instruction following, tool use (e.g., web search, Python code execution), and full chain-of-thought reasoning for enhanced debugging and trustworthiness.
Adjustable reasoning effort levels (low, medium, high) via prompts.
Full-parameter fine-tuning for tailored applications.
Underwent rigorous safety training and evaluation under OpenAI's Preparedness Framework, including external expert reviews.
System Requirements: While specific details aren't provided, based on parameter sizes, gpt-oss-20b is suitable for mid-range PCs (e.g., 16-32GB RAM/VRAM), while gpt-oss-120b may require high-end hardware like 80GB+ VRAM (e.g., A100/H100 GPUs) for efficient local runs. Quantization can help on consumer setups.
How to Run Locally: Available on Hugging Face; use Transformers: from transformers import AutoModelForCausalLM; model = AutoModelForCausalLM.from_pretrained('openai/gpt-oss-20b'). Compatible with Ollama or llama.cpp for quantized versions. An interactive playground is at https://gpt-oss.com/ for testing.

Pros: Permissive Apache 2.0 license for commercial use; competitive benchmarks (e.g., MMLU: 90.0 for 120b, 85.3 for 20b; GPQA Diamond: 80.1 for 120b); strong in agentic workflows and safety-focused design.
Cons: Limited details on exact system requirements; may require significant hardware for the larger variant; focused on agentic tasks, potentially less versatile for creative generation without fine-tuning.
Use Cases: Building AI agents for automation, code execution tools, research in reasoning tasks, or customized enterprise solutions involving tool integration.
2. Llama 3.1 (Meta) - The Versatile LLM Powerhouse

Llama 3.1 from Meta is one of the most popular open-source LLMs in 2025, building on its predecessors with improved reasoning and multilingual support. Available in sizes from 8B to 405B parameters, the 8B and 70B variants are ideal for local PCs.
Key Features:
128K token context window for handling long documents.
Excels in text generation, code writing, and conversational AI.
Supports fine-tuning for custom apps like chatbots or summarizers.
System Requirements: 8GB RAM (CPU) or 6GB VRAM (GPU) for the 8B model; scales up for larger versions.

How to Run Locally: Use Ollama: ollama pull llama3.1 and ollama run llama3.1. For advanced setups, integrate with Hugging Face: from transformers import pipeline; generator = pipeline('text-generation', model='meta-llama/Llama-3.1-8B').
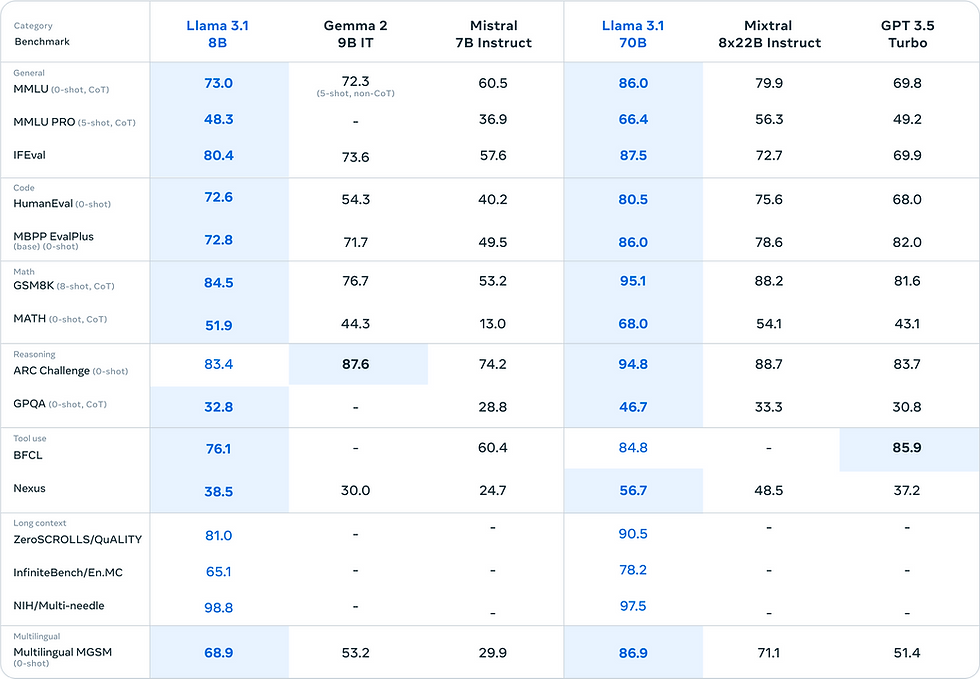
Pros: High performance on benchmarks like MT-Bench; community-driven improvements.
Cons: Larger models require powerful GPUs.
Use Cases: Personal assistants, content creation, or educational tools.
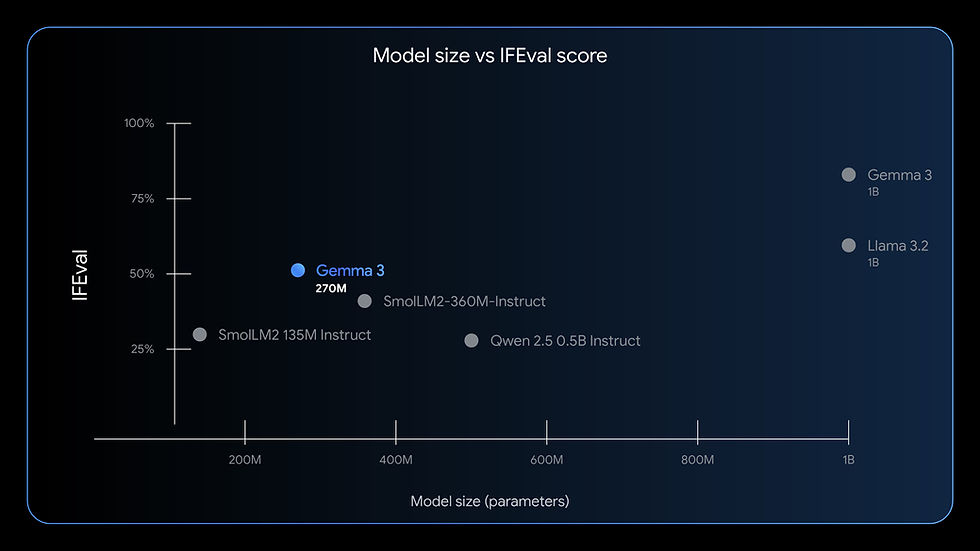
3.Gemma 3 (Google) - The Efficient Multimodal & Multilingual Specialist

Google's Gemma 3 family is a massive leap forward in 2025 for lightweight, locally-runnable models. Spanning a wide range of sizes from an incredibly compact 270M to a powerful 27B, Gemma 3 is designed for efficiency and versatility. It brings true multimodal understanding (text, image, and video) and best-in-class multilingual capabilities to hardware ranging from high-end workstations to everyday smartphones.

Key Features:
True Multimodal Understanding: Natively processes and analyzes images, text, and video, opening the door for more interactive and intelligent local applications.
Unparalleled Multilingual Capabilities: With support for over 140 languages, it's a top choice for building applications that can reach a global audience.
128K-Token Context Window: Allows the model to process and understand vast amounts of information, enabling more sophisticated and context-aware features.
Advanced Quantization (QAT): Utilizes Quantization-Aware Training to dramatically reduce memory requirements, allowing powerful models like the 27B variant to run efficiently on consumer-grade GPUs.
System Requirements: The 27B model runs on consumer GPUs (e.g., NVIDIA RTX 3090) thanks to QAT. Smaller variants, like the 270M, are so efficient they can run on smartphones using a tiny fraction of the battery.
How to Run Locally: Via Ollama: ollama pull gemma3. Or Hugging Face: from transformers import AutoModelForCausalLM; model = AutoModelForCausalLM.from_pretrained('google/gemma-3-27b').
Pros: Excellent performance-to-size ratio across all variants; best-in-class multilingual support; strong multimodal capabilities for a local model.
Cons: The new, ultra-light 270M model is designed for task-specific fine-tuning and is less suited for complex, general conversation out of the box.
Use Cases: Building a fleet of small, specialized models (e.g., for sentiment analysis or data extraction), on-device mobile AI applications, creative tools like story generators, and applications requiring user privacy.
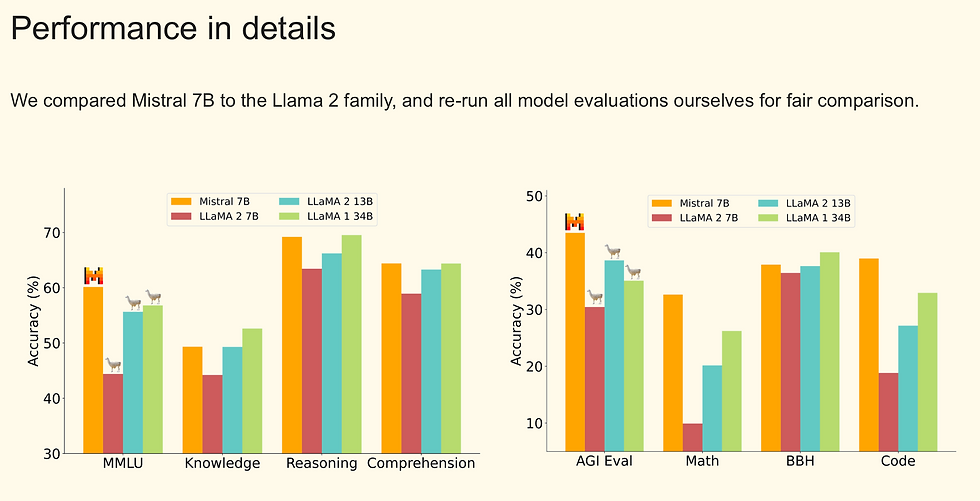
4. Mistral 7B (Mistral AI) - Speedy Multilingual LLM

Mistral 7B is a compact yet powerful LLM, praised for its efficiency in 2025. With 7B parameters, it uses Sliding Window Attention for rapid inference, outperforming larger models in speed.
Key Features:
32K-128K context; supports 80+ languages and function calling.
Fine-tuned variants for coding and math.
Apache 2.0 license for commercial use.
System Requirements: 8GB RAM; runs smoothly on integrated GPUs.
How to Run Locally: Ollama command: ollama pull mistral. Hugging Face: pipeline('text-generation', model='mistralai/Mistral-7B-v0.3').
Pros: Fast generation; low hallucination rates.
Cons: May need fine-tuning for specialized tasks.
Use Cases: Translation tools, code assistants, or real-time chat.
5. Phi-4 (Microsoft) - Compact LLM for Resource-Limited PCs
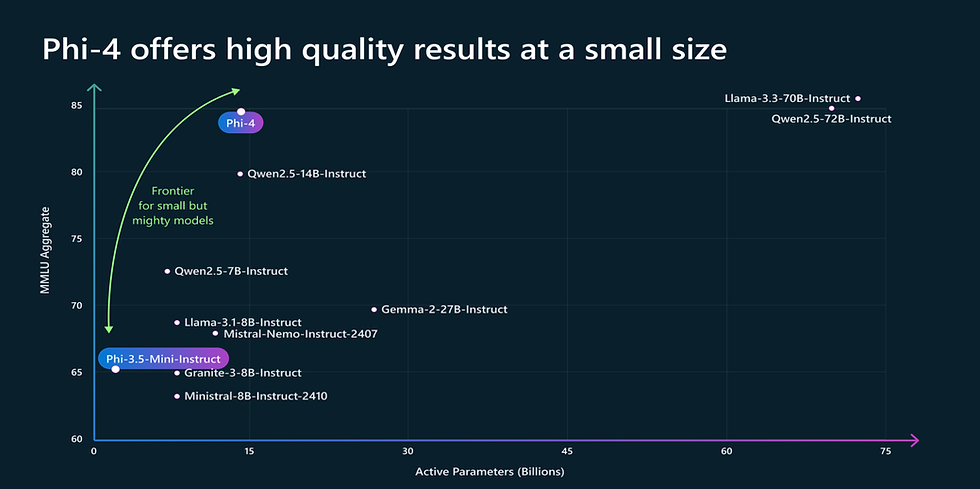
Microsoft's Phi-4 is designed for local and on-device use, with a modest parameter count that punches above its weight in coding and reasoning. It's a top choice for 2025's edge AI applications.
Key Features:
Up to 128K context; multimodal support (text + images).
Excels in math, code, and multi-lingual tasks.
Optimized for offline inference.
System Requirements: 4-6GB RAM; ideal for laptops without discrete GPUs.
How to Run Locally: Ollama: ollama pull phi3. Transformers: model = AutoModelForCausalLM.from_pretrained('microsoft/Phi-4').
Pros: Excellent performance-to-size ratio; runs on consumer hardware.
Cons: Smaller knowledge base than giants like Llama.
Use Cases: Educational software, lightweight bots, or mobile AI.
6. DeepSeek Coder V3 (DeepSeek AI) - The Specialist for Local Code Generation

For developers running AI on their own machines, a specialized coding model is often non-negotiable. DeepSeek Coder V3 has cemented its place in 2025 as the leading open-source choice for code generation, completion, and debugging. It consistently benchmarks at or above proprietary models like GitHub Copilot Enterprise in terms of accuracy and utility.
Key Features:
Trained on a massive corpus of code from over 100 programming languages.
Advanced code completion that understands the entire repository context.
"Self-debug" capability, where the model can identify and suggest fixes for its own generated code.
Available in sizes from 8B to 67B, with the 8B being perfect for laptops.
System Requirements: 8GB RAM for the 8B model; works surprisingly well on CPU-only setups.
How to Run Locally: Ollama: ollama pull deepseek-coder-v3. For VS Code integration, use the Continue extension and connect it to your local Ollama instance.
Pros: Unmatched coding accuracy in the open-source space; excellent for complex languages like Rust and C++.
Cons: Highly specialized; less capable at general creative writing or conversation than models like Llama 3.1.
Use Cases: Code autocompletion, writing unit tests, translating code between languages, or learning a new programming framework.
7. Stable Diffusion (Stability AI) - Leading Open-Source Image Generator
For visual AI, Stable Diffusion remains the go-to open-source model in 2025, generating photorealistic images from text prompts. Variants like SDXL and SD 3.5 offer enhanced quality.
Key Features:
Diffusion-based; supports inpainting, outpainting, and video generation (via Stable Video Diffusion).
Customizable with ControlNet for precise edits.
Millions of community fine-tunes on Hugging Face.
System Requirements: 4-8GB VRAM; CPU fallback available but slower.
How to Run Locally: Install Diffusers: pip install diffusers; then from diffusers import StableDiffusionPipeline; pipe = StableDiffusionPipeline.from_pretrained('stabilityai/stable-diffusion-xl-base-1.0').
Pros: High customization; no cloud dependency.
Cons: Can distort complex elements like hands; compute-intensive.
Use Cases: Art creation, product mockups, or game assets.
8. FLUX.1 (Black Forest Labs) - Advanced Image Gen for Pros
FLUX.1 is a 2025 standout for open-source image generation, surpassing Stable Diffusion in prompt adherence and diversity. Variants like [schnell] are optimized for speed.
Key Features:
12B parameters; hybrid transformer architecture.
Excellent text rendering and editing tools (e.g., FLUX.1 Fill).
Apache 2.0 for [schnell] variant.
System Requirements: 8-12GB VRAM; [schnell] runs on mid-range GPUs.
How to Run Locally: Via BentoML or Diffusers: Check GitHub for BentoDiffusion/flux-timestep-distilled.
Pros: Superior visual quality; fast inference.
Cons: Commercial restrictions on some variants.
Use Cases: Professional design, marketing visuals, or AI art experiments.
9. Whisper (OpenAI) - Top Speech-to-Text Model
Whisper is the premier open-source speech AI for local use, handling transcription and translation across 100+ languages. It's lightweight and accurate for 2025's audio tasks.
Key Features:
Handles noisy audio; supports real-time processing.
Models from tiny (39M params) to large (1.55B).
Integrates with TTS for full voice apps.
System Requirements: 2-4GB RAM; GPU optional for speed.
How to Run Locally: pip install openai-whisper; whisper audio.mp3 --model medium.
Pros: High accuracy; offline transcription.
Cons: Slower on CPU for long files.
Use Cases: Podcast transcription, language learning, or accessibility tools.
Challenges and Considerations for Local AI
While running AI locally is empowering, it's important to be realistic about the challenges:
Hardware is a Bottleneck: The performance of these models is directly tied to your PC's VRAM and processing power. A high-end experience with the largest models still requires a significant investment in hardware.
Complexity and Bugs: While tools like Ollama have simplified setup, you can still run into driver issues, dependency conflicts, and model incompatibilities. Be prepared for some troubleshooting.
Model Limitations: Open-source models can sometimes be less polished than their commercial counterparts, occasionally producing nonsensical outputs or requiring more specific prompting techniques.
Comparison Table: Top 4 Open-Source LLMs for Local PC Use
Comparison Table: Top Open-Source LLMs for Local PC (December 2025)
Model | Parameter Size | Key Strengths | Minimum Hardware | Best For |
Llama 3.3 70B | 70B | Matches 405B performance, efficient | 32GB RAM / 16GB VRAM | General-purpose powerhouse |
Qwen 2.5 Coder 32B | 32B | Best coding accuracy (92.7% HumanEval) | 24GB RAM / 12GB VRAM | Code generation |
Gemma 3 27B | 27B | Multimodal (text+image+video), 140 languages | 16GB RAM / 12GB VRAM | Multilingual, on-device AI |
gpt-oss-20b | 20B | Agentic tasks, reasoning, tool use | 16-32GB RAM / 8GB+ VRAM | AI agents, automation |
Llama 3.1 8B | 8B | Lightweight, versatile | 8GB RAM / 6GB VRAM | Budget builds |
Mistral 7B | 7B | Fast multilingual inference | 8GB RAM / 4GB VRAM | Speed-focused tasks |
Data sourced from official benchmarks and community testing (December 2025)
Key Takeaway: For most users in December 2025, Llama 3.3 70B offers the best performance-to-hardware ratio if you have a modern gaming PC. For coding specifically, Qwen 2.5 Coder 32B is the new king.
Conclusion: Empower Your PC with Open-Source AI in 2025
These top 9 open-source AI models—gpt-oss series, Llama 3.1, Gemma 2, Mistral 7B, Phi-4, DeepSeek Coder V3, Stable Diffusion, FLUX.1, and Whisper—represent the cutting edge of local AI technology. By running them on your PC, you gain control, privacy, and endless possibilities for innovation. Start with Ollama for LLMs or Diffusers for images, and experiment to find what fits your setup.
Looking ahead, the next frontier for local AI involves even greater efficiency. Expect to see advancements in 2-bit and 1-bit quantization, making it possible to run massive 100B+ parameter models on consumer-grade GPUs. Furthermore, the rise of powerful local multimodal models—capable of understanding text, images, and audio simultaneously—will unlock a new wave of applications, turning every PC into a true creative and analytical partner.
Stay updated with AI News Hub for more on "best local AI models 2025" and emerging trends. Which model will you try first? Share in the comments! Frequently Asked Questions (FAQs) on Open-Source AI Models
What is the best open-source AI model to run on a PC in December 2025?
It depends on your needs. For all-around powerful text and code generation, Llama 3.1 is a top choice. For efficiency, on-device use, and strong multimodal (text, image, video) capabilities, the new Gemma 3 family excels. For specialized coding tasks, DeepSeek Coder V3 is a leading option.
Can I run these AI models on my PC for free?
Yes. All 9 models listed are open-source or have permissive open-weight licenses, meaning they are free to download, run, and modify for personal and, in most cases, commercial use. This eliminates the need for subscriptions.
How much RAM or VRAM do I need to run a local AI?
It varies. Lightweight models like Mistral 7B or the smaller Gemma 3 variants can run on as little as 4-8GB of RAM. For larger models like Llama 3.1 (8B version), you should aim for at least 8GB of VRAM for good GPU performance, or 16GB of system RAM for CPU-based runs.
What is the easiest way to start running these models?
The simplest method for beginners is using a framework called Ollama. After a one-time setup, you can download and run a powerful model with a single command, such as ollama run llama3.1. For a more user-friendly interface, LM Studio is also a popular choice.
What is the best open-source model for generating images locally?
Stable Diffusion remains the most popular and customizable choice, with a massive community and many fine-tuned variations. For users seeking higher prompt adherence and visual quality out-of-the-box, FLUX.1 is a powerful new alternative.
Do I need a powerful GPU to run local AI?
While a GPU (especially NVIDIA with CUDA) dramatically speeds up performance, it's not always required. Many models have quantized versions (e.g., in GGUF format) that are highly optimized to run efficiently on a computer's CPU, making local AI accessible even on laptops without a dedicated graphics card.
Related Reading
AI Inference Costs 2025: Why Google TPUs Beat Nvidia GPUs by 4× : Our original deep-dive that predicted this migration
Nvidia to Google TPU Migration 2025: The $6.32B Inference Cost Crisis
AI Sports Predictions & AI Sports Analysis: Complete Guide to Machine Learning in Sports (2025)



Comments